
· 데이터 전환
운영 중인 데이터를 추출하여 새로운 정보 시스템에서 운영할 수 있도록 변환한 후 적재하는 일련의 과정
데이터 이행(Data Migration) 또는 데이터 이관이라고도 한다
ETL(Extraction/추출 -> Transformation/변환 -> Load/적재)
· 데이터 검증
원천 시스템의 데이터를 목적 시스템의 데이터로 전환하는 과정이 정상적으로 수행되었는지의 여부를 확인하는 과정
검증 방법과 검증 단계에 따라 분류할 수 있다
· 오류 데이터 측정 및 정제
고품질의 데이터를 운영 및 관리하기 위해 수행한다
데이터 품질 분석 -> 데이터 측정 -> 오류 데이터 정제
· 데이터베이스(DataBase)
공동으로 사용될 데이터를 중복을 배제하여 통합하고 저장하여 항상 사용할 수 있도록 운영하는 운영 데이터
- 통합된 데이터(Integrated Data) : 자료의 중복을 배제한 데이터의 모임
- 저장된 데이터(Stored Data) : 컴퓨터가 접근할 수 있는 저장 매체에 저장된 자료
- 운영 데이터(Operational Data) : 조직의 고유한 업무를 수행하는 데 반드시 필요한 자료
- 공용 데이터(Shared Data) : 여러 응용 시스템들이 공동으로 소유하고 유지하는 자료
· DBMS(DataBase Management System)
사용자의 요구에 따라 정보를 생성해주고 데이터를 관리해주는 소프트웨어
- 정의(Definition) 기능 - DDL : 데이터형과 구조에 대한 정의, 이용 방식, 제약 조건 명시
- 조작(Manipulation) 기능 - DML : 데이터 검색, 갱신, 삽입, 삭제
- 제어(Control) 기능 - DCL : 데이터의 무결성, 보안, 권한 검사, 병행 제어
· 스키마(Schema)
데이터베이스의 구조와 제약조건에 관한 전반적인 명세를 기술한 것
| 외부 스키마 | 사용자 또는 개발자가 개인의 입장에서 필요로 하는 데이터베이스의 논리적 구조를 정의한 것 |
| 개념 스키마 | 데이터 베이스의 전체적인 논리적 구조 필요로 하는 데이터를 종합한 조직 전체의 데이터베이스로 하나만 존재함 |
| 내부 스키마 | 물리적 저장장치의 입장에서 본 데이터베이스 구조 실제로 저장될 레코드의 형식, 저장 데이터 항목의 표현 방법, 내부 레코드의 물리적 순서 등을 나타냄 |
· 데이터베이스 설계 순서
1) 요구 조건 분석
요구 조건 명세서 작성
2) 개념적 설계
개념 스키마, 트랜잭션 모델링, E-R 모델
3) 논리적 설계
목표 DBMS에 맞는 논리 스키마 설계, 트랜잭션 인터페이스 설계
4) 물리적 설계
목표 DBMS에 맞는 물리적 구조의 데이터로 변환
5) 구현
목표 DBMS의 DDL로 데이터 베이스 생성, 트랜잭션 작성
· 개념적 설계(정보 모델링, 개념화) -> 개념 스키마 설계
현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정
개념 스키마 모델링과 트랜잭션 모델링을 병행 수행한다
요구 분석에서 나온 결과인 요구 조건 명세를 E-R다이어그램으로 작성한다
· 논리적 설계(데이터 모델링) -> 개념 스키마 평가 및 정제, 서로 다른 논리적 스키마 설계
현실 세계에서 발생하는 자료를 컴퓨터가 이해하고 처리할 수 있도록 변환하기 위해
특정 DBMS가 지원하는 논리적 자료 구조로 변환(mapping)시키는 과정
· 물리적 설계(데이터 구조화)
논리적 설계에서 논리적 구조로 표현된 데이터를 물리적 구조의 데이터로 변환하는 과정
파일의 저장 구조 및 액세스 경로를 결정하며, 테이블 정의서 및 명세서가 산출된다
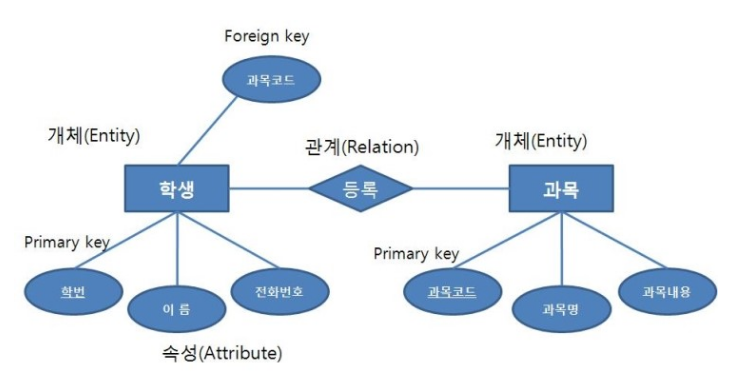
· 개체(Entity)
데이터 모델의 구성 요소로 데이터베이스에 표현하려는 것, 사람이 생각하는 개념이나 정보 단위 같은 현실 세계의 대상체
실세계에서 독립적으로 존재하는 유형, 무형의 정보로 서로 연관된 몇 개의 속성으로 구성된다
독립적으로 존재하거나 그 자체로서도 구별이 가능하며, 유일한 식별자(Unique Identifier)에 의해 식별된다
· 관계(Relationship)
개체와 개체 사이의 논리적인 연결
- 일 대 일(1:1)
- 일 대 다(1:N)
- 다 대 다(N:M)
· 데이터 모델 (개념적 설계)
현실 세계의 정보들을 단순화, 추상화하여 체계적으로 표현한 개념적 모형
| 데이터 모델에 표시할 요소 | |
| 구조(Structure) | 논리적으로 표현된 개체 타입들 간의 관계 |
| 연산(Operation) | 데이터베이스에 저장된 실제 데이터를 처리하는 작업에 대한 명세(데이터 조작 기본 도구) |
| 제약 조건(Constraint) | 데이터베이스에 저장될 수 있는 실제 데이터의 논리적인 제약 조건 |
· E-R(Entity-Relationship, 개체-관계) 모델
개체와 개체 간의 기본 요소로 현실 세계의 무질서한 데이터를 개념적인 논리 데이터로 표현하기 위한 방법
1976 피터 첸에 의해 제안, 개념적 데이터 모델의 가장 대표적인 것
· E-R 다이어그램
사각형 - 개체
마름모 - 관계
타원 - 속성
이중 타원 - 다중값 속성
밑줄 타원 - 기본키 속성
선- 개체 타입과 속성을 연결
· 릴레이션 구조
릴레이션(Relation)은 데이터들을 표(Table) 형태로 표현한 것
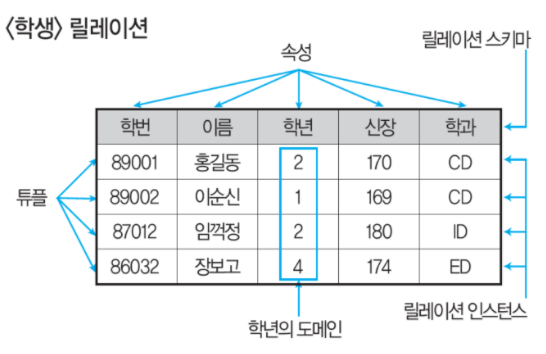
- 릴레이션 스키마 : 구조
- 릴레이션 인스턴스 : 값
- 속성(Attribute) : 열
데이터 베이스를 구성하는 가장 작은 논리적인 단위로 속성의 수를 디그리(Degree) 또는 차수라고 한다
파일 구조상의 데이터 항목 또는 데이터 필드에 해당된다
- 튜플(Tuple) : 행
릴레이션을 구성하는 각각의 행을 뜻하며 튜플은 속성의 모임으로 구성되며, 레코드와 같은 의미를 가진다
튜플의 수를 카디널리티(Cardinality) 또는 기수, 대응수라고 한다
- 도메인(Domain)
하나의 속성이 취할 수 있는 같은 타입의 원자(Atomic)값 들의 집합이다
도메인은 실제 속성 값의 합법 여부를 시스템이 검사하는 데에도 이용된다 (ex. 성별 -> 남or여 그 외의 값은 X)
· Key의 종류
1) 후보키(Candidate Key)
속성들 중에서 튜플을 유일하게 식별하기 위해 사용되는 속성들의 부분집합으로 기본키로 사용할 수 있는 속성들을 말한다
후보키는 유일성(Unique)과 최소성(Minimality)을 모두 만족시켜야 한다
| 유일성(Unique) | 하나의 키 값으로 하나의 튜플만을 유일하게 식별할 수 있어야 함 |
| 최소성(Minimality) | 키를 구성하는 속성 하나를 제거하면 유일하게 식별할 수 없도록 꼭 필요한 최소의 속성으로만 구성 |
2) 기본키(Primary Key)
후보키 중에서 특별히 선정된 메인 키(Key)로 중복된 값과 Null값을 가질 수 없고 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성이다
3) 대체키(Alternate Key) = 보조키
후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키
4) 슈퍼키(Super Key)
한 릴레이션 내에 있는 속성들의 집합으로 구성된 키로 모든 튜플 중 슈퍼키로 구성된 속성의 집합과 동일한 값은 없다
슈퍼키는 모든 튜플에 대해 유일성은 만족하지만 최소성은 만족하지 못한다
5) 외래키(Foreign Key)
다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합이다
외래키로 지정되면 참조 릴레이션의 기본키에 없는 값은 입력할 수 없다
· 무결성(Integrity)
데이터베이스에 저장된 데이터 값과 그것이 표현하는 현실 세계의 실제값이 일치하는 정확성을 의미한다
| 개체 무결성 | 기본키를 구성하는 어떤 속성도 Null값이나 중복값을 가질 수 없다 |
| 참조 무결성 | 외래키 값은 Null이거나 참조 릴레이션의 기본키 값과 동일해야 한다 |
· 관계 대수
DBMS에서 원하는 정보와 그 정보를 검색하기 위해서 어떻게 유도하는가를 기술하는 절차적인 언어
릴레이션을 처리하기 위해 연산자와 연산 규칙을 제공하며, 피연산자와 연산 결과가 모두 릴레이션이다
질의에 대한 해를 구하기 위해 수행해야 할 연산의 순서를 명시한다
· 관계 해석(Relational Calculus)
관계 데이터의 연산을 표현하는 방법
관계 데이터 모델의 제안자인 코드(E. F. Codd)가 수학의 술어 해석에 기반을 두고 제안했다
원하는 정보가 무엇이라는 것만 정의하는 비절차적 특징을 가진다
원하는 정보를 정의할 때에는 계산 수식을 이용한다
· 순수 관계 연산자
Select - σ(시그마)
선택 조건을 만족하는 튜플의 부분집합을 구하여 새로운 릴레이션을 만드는 연산
릴레이션에 해당하는 튜플(행)을 구하는 것으로 수평 연산이라고도 한다
Project - π(파이)
주어진 릴레이션에서 속성 리스트에 제시된 속성 값만을 추출하여 새로운 릴레이션을 만드는 연산
열에 해당하는 속성을 추출하는 것으로 수직 연산이라고도 한다
Join - ⋈
공통 속성을 중심으로 두 개의 릴레이션을 하나로 합쳐 새로운 릴레이션을 만드는 연산
Join의 결과는 Cartesian Product를 수행한 후 Select를 수행한 것과 같다
Diviwion - ÷
X ⊃ Y인 두 개의 릴레이션 R(X), S(Y)가 있을 때, R의 속성이 S의 속성값을 모두 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산
· 일반 집합 연산자
UNION(합집합) - ∪두 릴레이션에 존재하는 합집합을 구하되, 중복되는 튜플은 제거하는 연산이다합집합의 카디널리티는 두 릴레이션의 카디널리티보다 크지 않다
INTERSECTION(교집합) - ∩
두 릴레이션에 존재하는 튜플의 교집합을 구하는 연산이다
DIFFERENCE(차집합) - ㅡ
두 릴레이션에 존재하는 튜플의 차집합을 구하는 연산이다차집합의 카디널리티는 릴레이션 R의, 카디널리티보다 크지 않다
CARTESIAN PRODUCT(교차곱) - X
두 릴레이션에 있는 튜플들의 순서쌍을 구하는 연산이다
디그리 : 두 릴레이션의 디그리(속성의 수)를 더함
카디널리티 : 두 릴레이션의 카디널리티(튜플의 수)를 곱함
· 이상(Anomaly)
데이터들이 불필요하게 중복되어 릴레이션 조작에 예기치 않게 발생하는 곤란한 현상
- 삽입 이상(Insertion Anomaly)
의도와는 상관없이 원하지 않은 값들로 인해 삽입할 수 없게 되는 현상
- 삭제 이상(Deletion Anomaly)
의도와는 상관없는 값들도 삭제되어 연쇄 삭제가 발생하는 현상
- 갱신 이상(Update Anomaly)
튜플의 속성 값을 갱신할 때 일부 튜플의 정보만 갱신되어 정보에 불일치성이 생기는 현상
· 함수적 종속(Functional Dependency)
어떤 테이블 R에서 X와 Y를 각각 R의 속성 집합의 부분 집합이라고 예를 들어
속성 X의 값 각각에 대해 시간에 관계없이 항상 속성 Y의 값이 오직 하나만 연관되어 있을 때는
Y는 X에 함수적 종속 또는 X가 Y를 함수적으로 결정한다고 하고 X→Y로 표시한다
함수적 종속은 데이터의 의미를 표현하는 것으로 현실 세계를 표현하는 제약 조건이 되는 동시에 DB에서 항상 유지되어야 할 조건이다
| 완전 함수적 종속 | 테이블 R에서 속성 Y가 다른 속성 집합 X 전체에 대해 함수적 종속이면서 속성 집합 X의 어떠한 진부분 집합 Z(Z⊂X)에도 함수적 종속이 아닐 때 속성 Y는 속성 집합 X에 완전 함수적 종속이라고 한다 |
| 부분 함수적 종속 | 테이블 R에서 속성 Y가 다른 속성 집합 X 전체에 대해 함수적 종속이면서 속성 집합 X의 임의의 진부분 집합에 대해 함수적 종속일 때 속성 Y는 속성 집합 X에 대해 함주속 종속이라고 한다 |
· 정규화(Normalization)
테이블 속성들이 상호 종속적인 관계를 갖는 특성을 이용하여 테이블을 무손실 분해하는 과정
가능한 한 중복을 제거하여 삽입,삭제, 갱신 이상의 발생을 줄이는 것이다
· 반정규화(Denormalization)
정규화된 데이테 모델을 의도적으로 통합, 중복, 분리하여 정규화의 원칙을 위배하는 과정
시스템의 성능이 향상되고 관리 효율성은 증가하지만 데이터의 일관성 및 정합성이 저하될 수 있다
· 정규화의 과정 [도부이결다조]
0) 비정규 릴레이션
↓ 도메인이 원자값
1) 1NF(First Normal Form)
모든 속성의 도메인이 원자 값 만으로 되어 있는 정규형
↓ 부분적 함수 종속 제거
2) 2NF(Second Normal Form)
기본키가 아닌 모든 속성이 기본키에 대하여 완전 함수적 종속을 만족 시키는 정규형
↓ 이행적 함수 종속 제거
3) 3NF(Third Normal Form)
기본키가 아닌 모든 속성이 기본키에 대해 이행적 함수적 종속을 만족하지 않는 정규형
↓ 결정자이면서 후보키가 아닌 것 제거
4) BCNF
모든 결정자가 후보키인 정규형
↓ 다치 종속 제거 (A->C일때, A->->B)
5) 4NF(Fourth Normal Form)
A→B가 존재할 경우 R의 모든 속성이 A에 함수적 종속 관계를 만족하는 정규형
↓ 조인 종속성 이용 (테이블 R이 모든 프로젝션을 모두 조인한 결과와 동일한 경우 테이블 R은 조인 종속을 만족시킨다)
6) 5NF(Fifth Normal Form)
모든 조인 종속이 R의 후보키를 통해서만 성립되는 정규형
도메인이 원자값
부분적 함수 종속 제거
이행적 함수 종속 제거
결정자이면서 부보키가 아닌 것 제거
다치 족송 제거
조인 종속성 이용
· 중복 테이블 추가
작업의 효율성을 향상시키기 위해 테이블을 추가하는 것
| 집계 테이블 | 집계 테이블을 위한 테이블을 생성하고, 각 원본 테이블에 트리거를 설정하여 이용 |
| 진행 테이블 | 이력 관리 등을 목적으로 추가하는 테이블 |
| 특정 부분만을 포함하는 테이블 |
데이터가 많은 테이블의 특정 부분만을 사용하는 경우 해당 부분만으로 새로운 테이블 생성 |
· 시스템 카탈로그(System Catalog)
다양한 객체에 관한 정포를 포함하는 시스템 데이터베이스
카탈로그들이 생성되면 데이터 사전에 저장되기 때문에 좁은 의미로 데이터 사전(Data Dictionary)이라고도 한다
사용자를 포함하여 DBMS에서 지원하는 모든 데이터 객체에 대한 정의나 명세에 관한 정보를 유지 관리하는 시스템 테이블
· 트랜잭션(Transaction)
DB의 상태를 변화시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 모두 수행해야 할 일련의 연산들
병행 제어 및 회복 작업 시 처리되는 작업의 논리적 단위로 사용된다
사용자가 시스템에 대한서비스 요구 시 시스템이 응답하기 위한 상태 변환 과정의 작업 단위로 사용된다
· 트랜잭션의 특성
| Atomicity (원자성) |
모두 반영되도록 완료(Commit)되던지 아니면 전혀 반영되지 않도록 복구(Rollback)되어야 함 |
| Consistency (일관성) |
트랜잭션이 성공적으로 완료하면 언제나 일관성 있는 DB 상태로 변함 |
| Isolation (독립성, 격리성, 순차성) |
트랜잭션이 병행 실행 되는 경우 트랜잭션 실행중에 다른 트랜잭션 연산이 끼어들 수 없다 |
| Durability (영속성, 지속성) |
성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적을 반영되어야 함 |
· CRUD 분석
프로세스와 테이블 간에 CRUD 매트리스를 만들어 트랜잭션을 분석하는 것
많은 트랜잭션이 몰리는 테이블을 파악할 수 있어 디스크 구성 시 유용한 자료로 사용된다
Create 생성 / Read 읽기 / Update 갱신 / Delete 삭제
· 인덱스(Index, 색인)
데이터 레코드에 빠르게 접근하기 위해 <키 값, 포인터> 쌍으로 구성되는 데이터 구조
레코드가 저장된 물리적 구조에 접근하는 방법을 제공한다
인덱스를 통해 파일의 레코드에 빠르게 액세스할 수 있다
· 클러스터드 인덱스(Clusterd Index)
인덱스 키의 순서에 따라 데이터가 정렬되어 저장되어지는 방식
실제 데이터가 순서대로 저장되어 있어 인덱스를 검색하지 않아도 빠르게 원하는 데이터를 찾을 수 있다
· 넌클러스터드 인덱스(Non-Clusterd Index)
인덱스의 키 값만 정렬되어 있고 실제 데이터는 정렬되지 않는 방식
데이터 삽입, 삭제 발생 시 순서를 유지하기 위해 데이터를 재정렬해야 한다
· 뷰(View)
접근이 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 기본 테이블로부터 유도된 이름을 가지는 가상 테이블
뷰가 정의된 기본테이블이나 뷰를 사제하면 그 테이블이나 뷰를 기초로 정의된 다른 뷰도 삭제된다
정의 : CREATE / 제거 : DROP
· 파티션(Partition)
대용량 테이블이나 인덱스를 작은 논리적 단위인 파티션으로 나누는 것
대용량 DB의 경우 몇 개의 중요한 테이블에만 집중되므로 해당 테이블을 작은 단위로 나눠 분산시키면 성능 저하를 방지, 데이터 관리도 쉬워진다
데이터 처리는 테이블 단위로, 데이터 저장은 파티션 별로 수행된다
| 범위 분할 (Range) |
지정한 열의 값을 기준으로 분할 (ex.일별, 월별, 분기별) |
| 해시 분할 (Hash) |
해시 함수를 적용한 결과 값에 따라 데이터를 분할함 특정 파티션에 데이터가 집중되는 범위 분할의 단점을 보완한 것으로 데이터를 고르게 분산할 때 유용함 특정 데이터가 어디에 있는지 판단할 수 없는 단점이 있다 (ex.고객번호, 주민번호 -> 데이터가 고른 컬럼) |
| 조합 분할 (Composite) |
범위분할로 분할한 다음 -> 해시 함수를 적용하여 다시 분할 하는 방식 범위 분할한 파티션이 너무 커서 관리가 어려울 때 유용함 |
· 분산 데이터베이스의 목표
| 위치 투명성 (Location Transparency) |
데이터베이스의 실제 위치를 알 필요 없이 논리적인 명칭 만으로 액세스 할 수 있음 |
| 중복 투명성 (Replication Transparency) |
동일 데이터가 여러 군데 중복되어 있더라도 사용자는 하나의 데이터만 존재하는 것처럼 사용하고, 시스템은 자동으로 여러 자료에 대한 작업을 수행함 |
| 병행 투명성 (Concurrency Transparency) |
분산 데이터베이스와 관련된 다수의 트랜잭션들이 동시에 실현되더라도 해당 트랜잭션의 결과는 영향을 받지 않음 |
| 장애 투명성 (Failure Transparency) |
트랜잭션, DBMS, 네트워크, 컴퓨터 장애에도 불구하고 트랜잭션을 정확하게 처리함 |
· RTO(Recovery Time Objective) - 목표 복구 시간
비상사태 또는 업무 중단 시점으로부터 복구되어 가동될 때까지의 소요 시간 (장애 발생 후 4시간 내 복구 가능)
· RPO(Recovery Point Objective) - 목표 복구 시점
비상 사태 또는 업무 중단 시점으로부터 데이터를 복구할 수 있는 기준점 (장애 발생 전 지난 주에 백업 시켜 둔 원본으로 복구 가능)
· 암호화(Encryption)
송신자가 지정한 수진자 이외에는 그 내용을 알 수 없도록 평문 -> 암호문 으로 변환 하는 것
- 암호화(Encryption) : 평문 -> 암호문
- 복호화(Decryption) : 암호문 -> 평문
| 암호화 기법 |
| · 개인키 암호 방식(Private Key Encryption) -> 대칭키 · 공개키 암호 방식(Public Key Encryption) -> 비대칭키 |
· 접근 통제
| 종류 | |
| 임의 접근통제 (DAC) |
Discretionary Access Control 데이터에 접근하는 사용자의 신원에 따라 접근 권한을 부여하는 방식 데이터 소유자가 접근통제 권한을 지정하고 제어한다 객체를 생성한 사용자가 객체에 대한 모든 권한을 부여받고, 부여된 권한을 다른 사용자에게 허가할 수 있다 |
| 강제 접근통제 (MAC) |
Mandatory Access Control 주체와 객체의 등급을 비교하여 접근 권한을 부여하는 방식 시스템이 접근통제 권한을 지정한다 데이터베이스 객체별로 보안 등급을 부여할 수 있고 사용자별로 인가 등급을 부여할 수 있다 |
| 역할기반 접근통제 (RBAC) |
Role Based Access Control 사용자의 역할에 따라 접근 권한을 부여하는 방식 중앙관리자가 접근통제 권한을 지정한다 임의 접근통제와 강제 접근통제의 단점을 보완한 다중 프로그래밍 환경에 최적화된 방식이다 |
· 스토리지(Storage)
단일 디스크로 처리할 수 없는 대용량 데이터를 저장하기 위해 서버와 저장장치를 연결하는 기술
| 종류 | |
| DAS |
Direct Attached Storage 서버와 저장장치를 전용 케이블로 직접 연결하는 방식 일반 가정 등에서 컴퓨터에 외장하드를 연결하는 것이 해당된다 직접 연결 방식이므로 다른 서버에서 접근할 수 없고 파일을 공유할 수 없다 |
| NAS | Network Attached Storage 서버와 저장장치를 네트워크를 통해 연결하는 방식 별도의 파일 관리 기능이 있는 NAS Storage가 내장된 저장장치를 직접 관리한다 Ethernet 스위치를 통해 다른 서버가 스토리지에 접근할 수 있어 파일 공유가 가능하다 |
| SAN | Storage Area Network DAS의 빠른 처리 + NAS의 파일 공유 장점 혼합 서버와 저장장치를 연결하는 전용 네트워크를 별도로 구성하는 방식 파이버 채널(Fibre Channel, 광 채널) 스위치를 이용하여 네트워크를 구성한다 광 케이블로 연결하므로 처리 속도가 빠르다 |
· 자료 구조
기억장치의 공간 내에 저장하는 방법과 자료 간의 관계, 처리 방법 등을 연구 분석 하는 것
선형 : 배열, 선형리스트(연속/연결리스트), 스택, 큐, 데크
비선형 : 트리, 그래프
1) 배열(Array)
크기와 형이 동일한 자료들이 순서대로 나열된 자료의 잡합
반복적인 데이터 처리 작업에 적합한 정적인 구조로, 기억장소의 추가가 어렵다
2) 스택(Stack)
리스트의 한쪽 끝으로만 자료의 삽입, 삭제가 이루어지는 후입선출(LIFO)구조 이다
Overflow : 저장 공간이 없는 상태에서 데이터 삽입이 일어날 때
Underflow : 삭제할 데이터가 없는 상태에서 삭제가 일어날 때
3) 큐(Queue)
리스트의 한쪽에서는 삽입 작업, 다른 한쪽에서는 삭제작업이 이루어지는 선입선출(FIFO)구조 이다
프런트(Front) 포인터 : 시작을 표시
리어(Rear) 포인터 : 끝을 표시
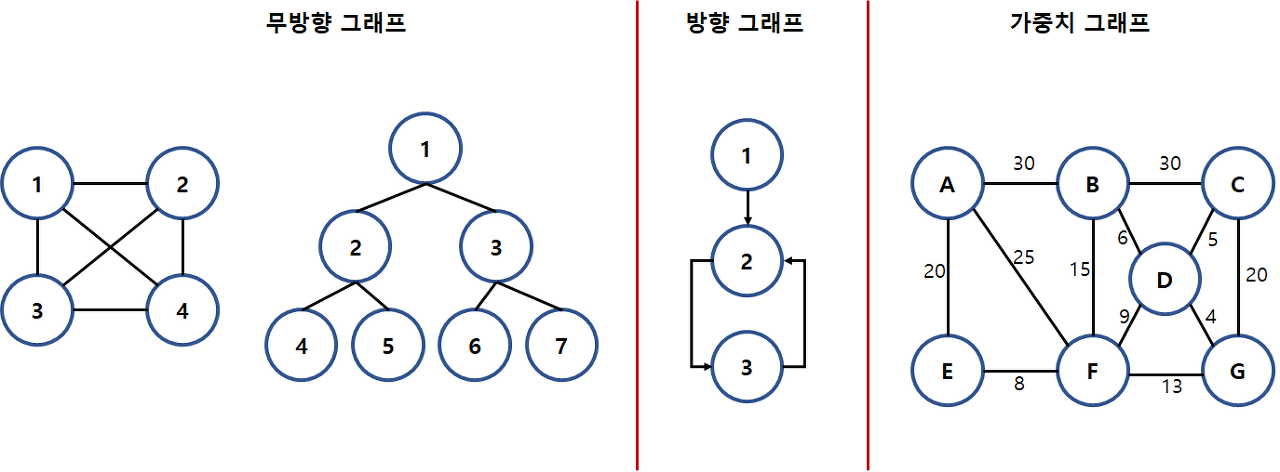
4-1) 그래프(Graph)
정점(Vertex)과 간선(Edge)의 두 집합으로 이루어진 자료 구조
사이클(순환)이 없는 그래프를 트리라고 하며, 간선의 방향성 유무에 따라 나눠진다
| 최대 간선 수 (n은 정점의 개수) | |
| 방향 그래프 | n(n-1) |
| 무방향 그래프 | n(n-1) / 2 |
| 무방향 그래프 (Undirected Graph) |
간선을 통해 양방향으로 갈 수 있는 그래프로 정점 A와 정점 B를 연결하는 간선은 (A,B), (B,A) 이다 |
| 방향 그래프 (Directed Graph) |
간선에 방향성이 존재하는 그래프로 방향이 있는 A -> B로 갈 수 있으며 간선은 (A, B)로 표시한다 |
| 가중치 그래프 (Weighted Graph) |
간선을 이동하는데 비용이나 가중치가 할당된 그래프로 네트워크라고도 한다 |
4-2) 그래프의 탐색
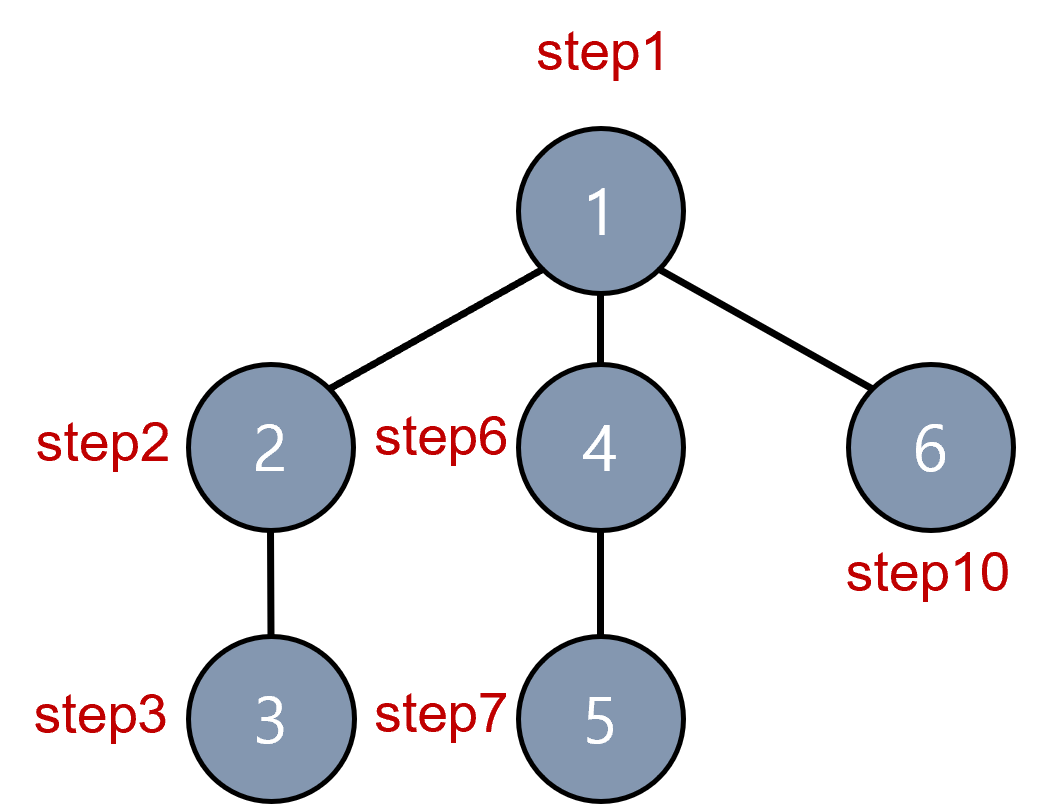
하나의 정점으로부터 시작하여 차례대로 모든 정점들을 한 번씩 방문하여 원하는 데이터를 찾는 방법
검색 속도는 너비 우선 탐색이 빠르나 깊이 우선 탐색이 더 간단하다
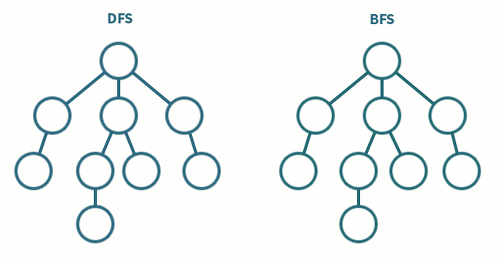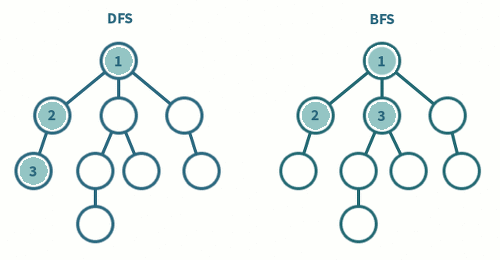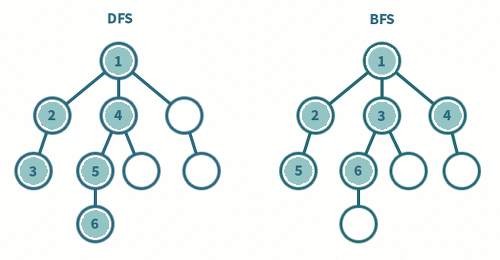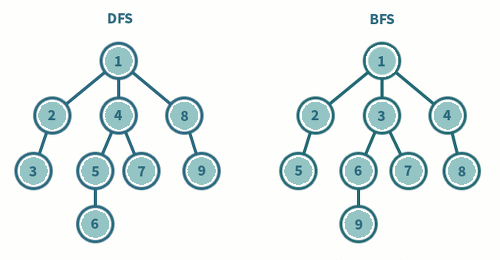
- 깊이 우선 탐색(DFS, Depth-First Search)
DFS란 정의와 같이 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘이다 스택 자료구조를 이용하여 표현(LIFO 방식)
즉, 그래프를 탐색 할때 특정한 경로로 쭉 타고 밑바닥까지 내려간 후 막다른 길에 도착하면 다시 돌아와 다른 경로로 탐색하는 것
| 동작원리 | 스택 |
| 구현방법 | 재귀 함수 |
| 장단점 | 그래프의 깊이가 깊을수록 빠르나 메모리가 적다 |
| 시간 복잡도 | 인접행렬 : O(n^2) / 인접리스트 : O(n+e) |
| 적용 예시 | 길 찾기, 미로 문제, 경로의 특징을 저장해야 하는 경우 |
- 너비 우선 탐색(BFS, Breadth-First Search)
BFS란 쉽게 말해 가까운 노드부터 탐색하는 알고리즘이다 큐 자료구조를 이용하여 표현(FIFO 방식)
즉, 그래프를 탐색 할때 가까운 노드들을 우선적으로 방문하고 멀리있는 노드를 나중에 방문한다
| 동작원리 | 큐 |
| 구현방법 | 큐 |
| 장단점 | 찾는 노드가 인접할 때 유리하나 노드가 많을 수록 메모리를 많이 소비함 |
| 시간 복잡도 | 인접행렬 : O(n^2) / 인접리스트 : O(n+e) |
| 적용 예시 | 길 찾기, 라우팅, 웹 크롤러, 그래프에서 주변 위치 찾기 |
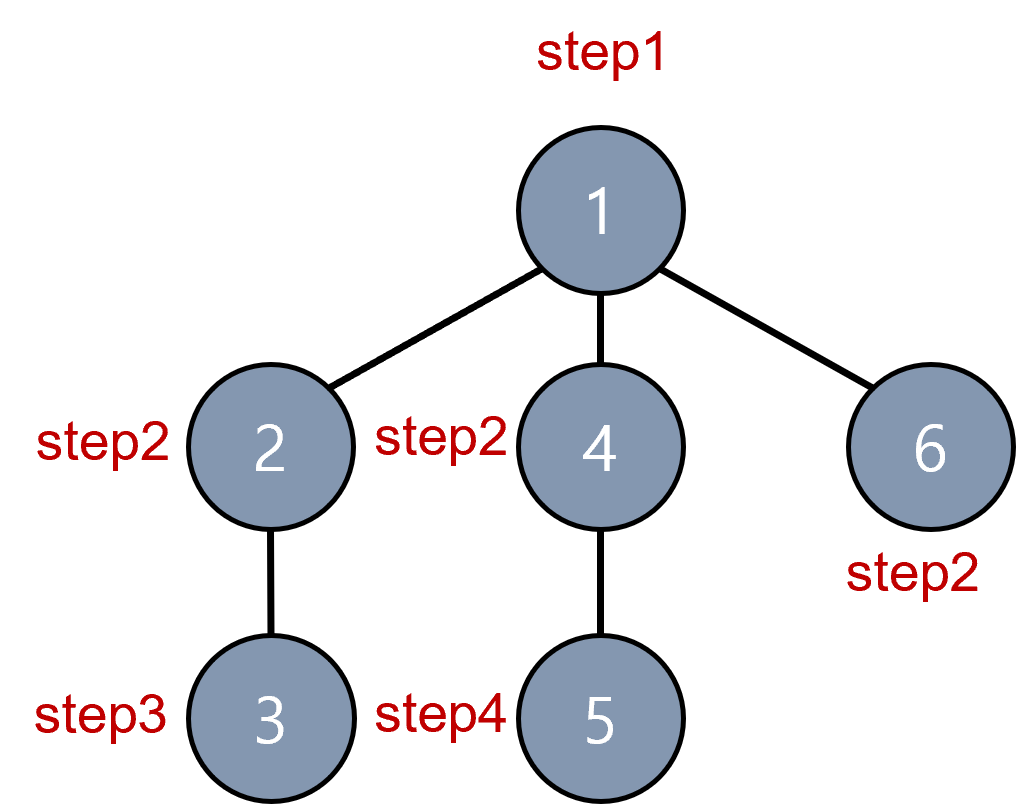
5-1) 트리(Tree)
정점(Node)과 선분(Branch)을 이용하여 사이클을 이루지 않도록 구성한 그래프의 특수한 형태
하나의 루트 노드와 0개 이상의 하위 트리로 구성되어 있다
데이터를 순차적으로 저장하지 않기 때문에 비선형 자료구조이다
트리내에 또 다른 트리가 있는 재귀적 자료구조이다
단순 순환(Loop)을 갖지 않고, 연결된 무방향 그래프 구조이다
노드 간에 부모 자식 관계를 갖고 있는 계층형 자료구조이며 모든 자식 노드는 하나의 부모 노드만 갖는다
노드가 n개인 트리는 항상 n-1개의 간선(edge)을 가진다
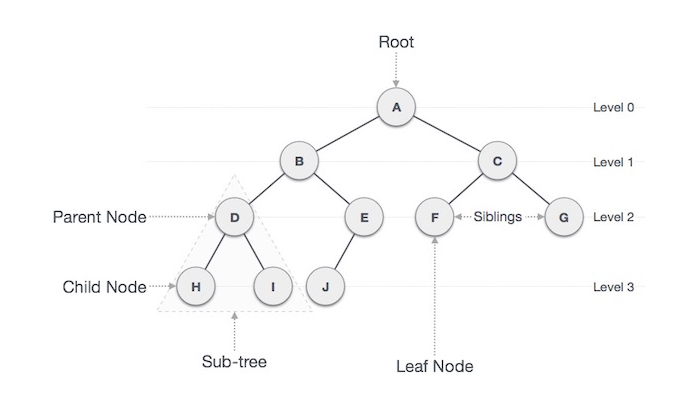
- 노드 (Node)
트리를 구성하고 있는 기본 요소
노드에는 키 또는 값과 하위 노드에 대한 포인터를 가지고 있음.
A, B, C, D, E, F, G, H, I, J
- 간선 (Edge)
노드와 노드 간의 연결선
- 디그리(Degree) = 차수
각 노드에서 뻗어나온 가지의 수
A = 2, B =2, C =2, E = 1
- 트리의 디그리
노드들의 디그리 중 가장 많은 수
디그리 2가 가장 많다 -> A, B, C, D
- 루트 노드 (Root Node), 근 노드
트리 구조에서 부모가 없는 최상위 노드
root node : A
- 부모 노드 (Parent Node)
자식 노드를 가진 노드
H, I에 부모 노드는 D
- 자식 노드 (Child node)
부모 노드의 하위 노드
노드 D의 자식 노드는 H, I
- 형제 노드 (Sibling node)
같은 부모를 가지는 노드
H, I는 같은 부모를 가지는 형제 노드
- 외부 노드(external node, outer node), 단말 노드 (terminal node), 리프 노드(leaf node)
자식 노드가 없는 노드
H, I, J, F, G
- 내부 노드 (internal node, inner node), 비 단말 노드 (non-terminal node), 가지 노드 (branch node)
자식 노드 하나 이상 가진 노드
A, B, C, D, E
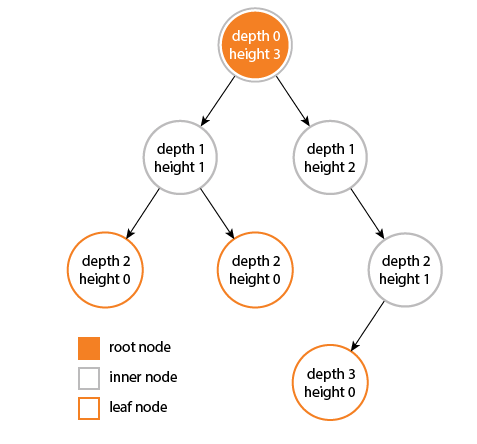
- 깊이 (depth)
루트에서 어떤 노드까지의 간선(Edge) 수
- 높이 (height)
어떤 노드에서 리프 노드까지 가장 긴 경로의 간선(Edge) 수
- Level
루트에서 어떤 노드까지의 간선(Edge) 수
- Path
한 노드에서 다른 한 노드에 이르는 길 사이에 놓여있는 노드들의 순서
A & H 경로 : A-B-D-H
- Path Length
해당 경로에 있는 총노드의 수
A & H 경로 길이 : 4
- Size
자신을 포함한 자손의 노드 수
노드 B의 size : 6
- Width
레벨에 있는 노드 수
Level 2 width : 4
- Breadth
리프 노드의 수
- Distance
두 노드 사이의 최단 경로에 있는 간선(Edge)의 수
D와 J의 Distance : 3
- Order
부모 노드가 가질 수 있는 최대 자식의 수
Order 3 : 부모 노드는 최대 3명의 자식을 가질 수 있다.
5-2) 트리의 종류
- 이진 트리(Binary Tree)
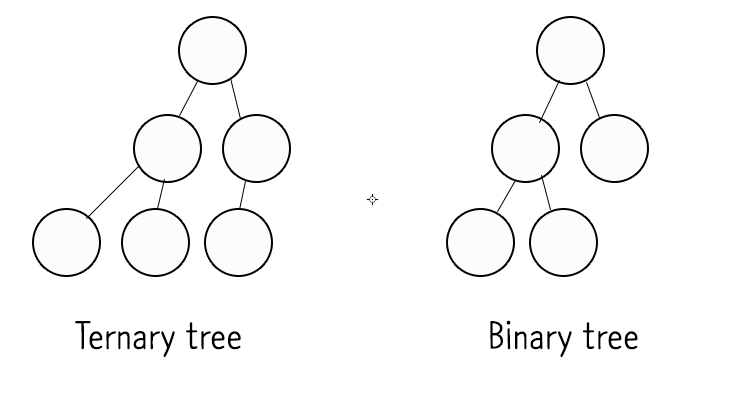
Ternary tree : 자식 노드를 2개 이상 갖고 있는 트리
Binary tree : 부모 노드가 자식 노드를 최대 2개씩만 갖고있는 트리.
- 이진 검색 트리(Binary Search Tree)

Binary tree : 노드들간의 대소관계는 고려하지 않는다.
Binary search tree : left child와 그 이하 노드들의 데이터가 현재 노드(부모 노드)의 데이터 보다 작아야 하고,
right child와 그 이하 노드들의 데이터가 현재 노드(부모 노드)의 데이터 보다 커야한다
- 완전 이진 트리(Complete Binary Tree)
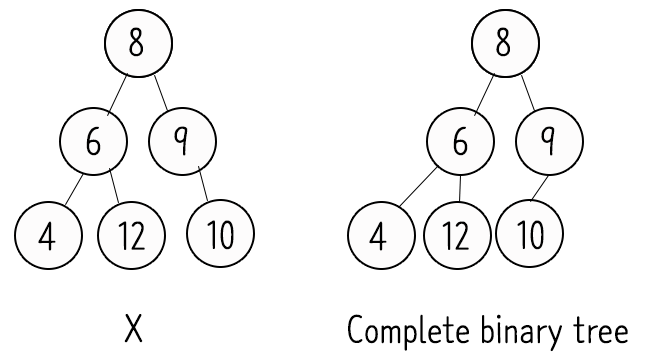
Complete binary tree : 마지막 레벨을 제외한 모든 서브트리의 레벨이 같아야 하고, 마지막 레벨은 왼쪽부터 채워져 있어야 함
- 정 이진 트리(Full Binary Tree)
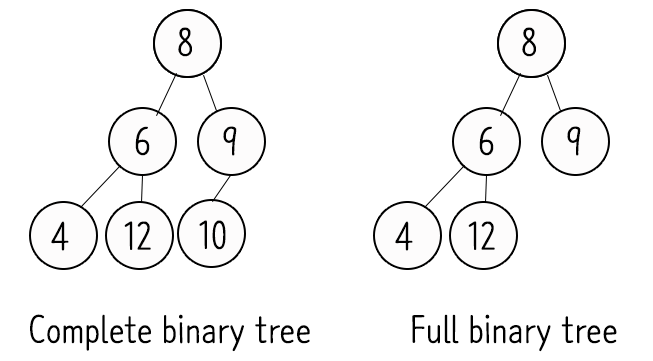
Full binary tree : 자식 노드가 아예 없거나, 최대 둘뿐인 tree. 자식을 하나만 가진 노드가 없어야 한다
- 포화 이진 트리(Perfect Binary Tree)

Perfect binary tree : 완벽한 피라미드 형태로 빈공간 없이 모든 노드가 2개의 자식을 갖고 있는 트리
5-3) 트리의 순회
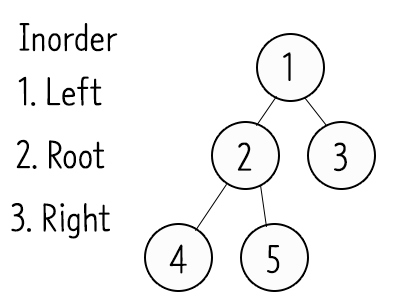
- 중위순회(Inorder) : Left -> Root -> Right
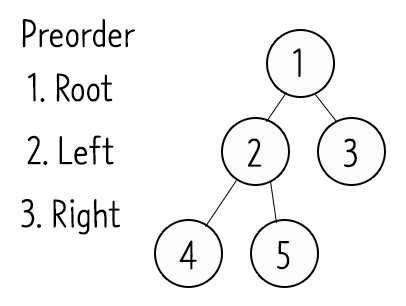
- 전위순회(Preorder) : Root -> Left -> Right
- 후위순회(Postorder) : Left -> Right -> Root
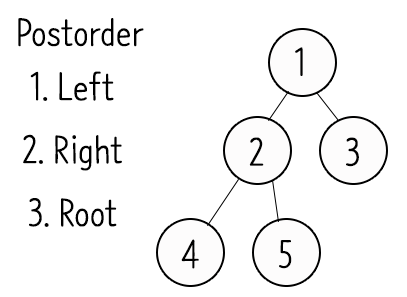
6) 수식 표기법
- Infix → Prefix (중위 → 전위)
수식에서 연산자를 해당 피연산자 2개의 앞(왼쪽)에 오도록 이동시킨다
| X = A / B * ( C + D ) + E → X +*/ AB + CDE |
- Infix → Postfix (중위 → 후위)
수식에서 해당 연산자를 피연산자 2개의 뒤(오른쪽)에 오도록 이동시킨다
| X = A / B * ( C + D ) + E → XAB / CD +* E = |
- Postfix → Infix (후위 → 중위)
연산자를 해당 피연산자 두 개의 뒤로 이동한 것이므로 연산자를 다시 해당 피연산자 두 개의 가운데로 이동시킨다
| ABC -/ DEF +*+ → A / (B - C) + D * (E+F) |
· 정렬
1) 삽입 정렬(Insertion Sort)
가장 간단한 정렬 방식으로, 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬하는 방식
평균과 최악 수행 시간 복잡도 : O(n²)
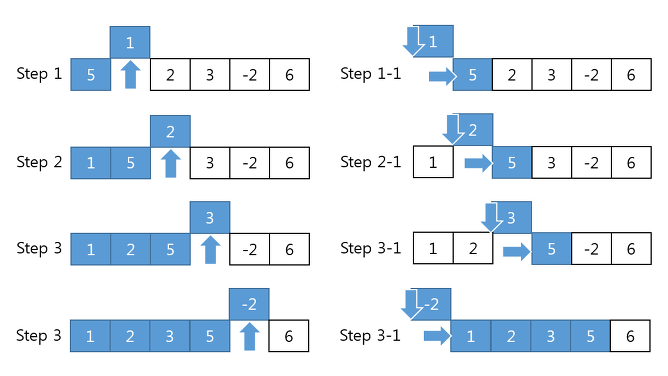
2) 선택 정렬(Selection Sort)
n개의 레코드 중에서 최소값을 찾아 첫번째 레코드에 위치시키고,
나머지 (n-1)개 중에서 다시 최소값을 찾아 두번째 레코드 위치에 놓는 방식을 반복하여 정렬하는 방식
평균과 최악 수행 시간 복잡도 : O(n²)

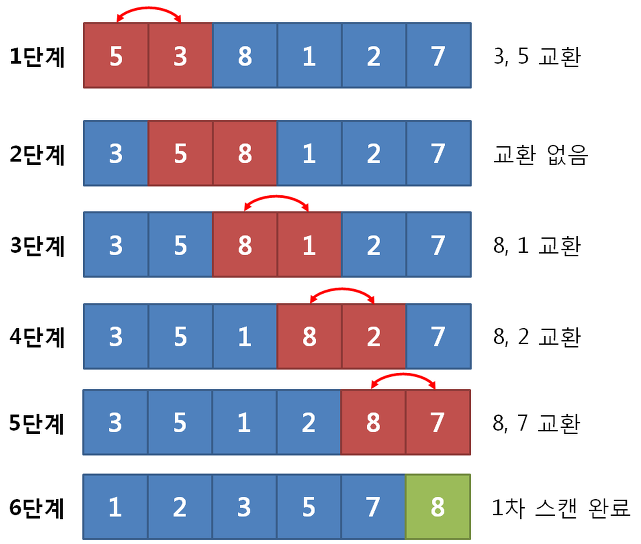
3) 버블 정렬(Bubble Sort)
주어진 파일에서 인접한 두 개의 레코드 키 값을 비교하여 그 크기에 따라 레코드의 위치를 서로 교환하는 정렬 방식
평균과 최악 수행 시간 복잡도 : O(n²)
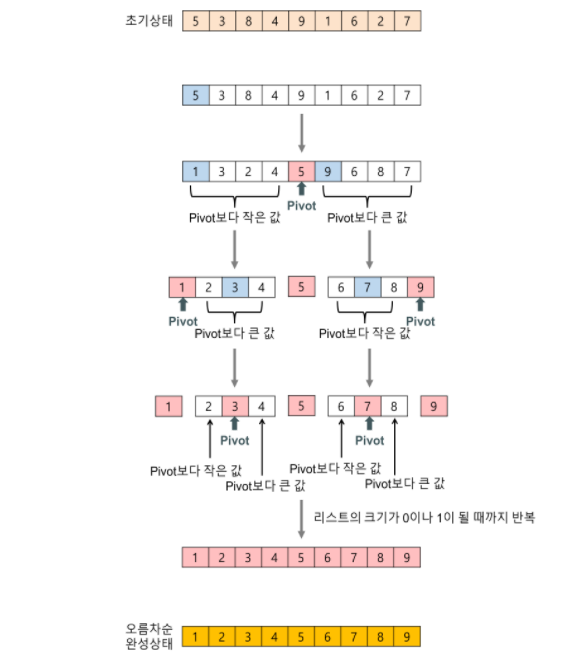
4) 퀵 정렬(Quick Sort)
키를 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽 서브 파일에 분해시키는 과정을 반복하는 정렬
레코드의 많은 자료 이동을 없애고 하나의 파일을 부분적으로 나누어 가며 정렬한다
평균 수행 시간 복잡도 : O(nlog₂n)
최악 수행 시간 복잡도 : O(n²)
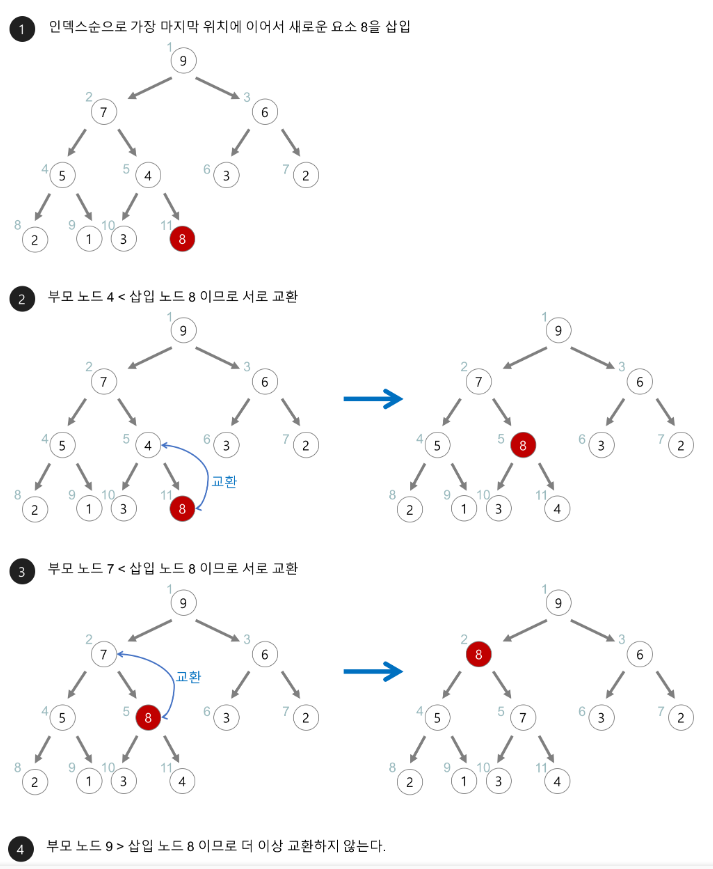
5) 힙 정렬(Heap Sort)
전이진 트리를 이용한 정렬 방식으로 전이진 트리(Complete Binary Tree)를 Heap Tree로 변환하여 정렬한다
평균과 최악 수행 시간 복잡도 : O(nlog₂n)
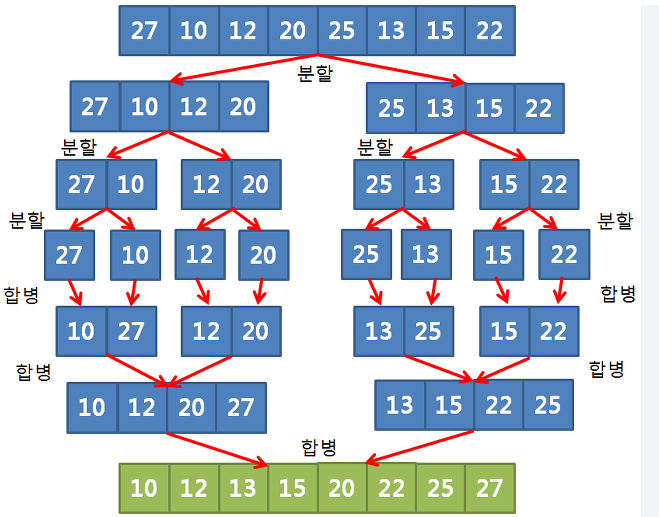
6) 2-Way 합병 정렬(Merge Sort)
이미 정렬 되어 있는 두 개의 파일을 한 개의 파일로 병합하는 정렬 방식
평균과 최악 수행 시간 복잡도 : O(nlog₂n)
· 통합 구현
사용자의 요구사항에 맞춰 송수신 모듈과 중계 모듈 간의 연계를 구현하는 것으로
송수신 방식이나 시스템 아키텍처 구성, 송수신 모듈 구현 방법 등에 따라 다르므로 사용자의 요구사항과 구축 환경에 적합한 방식을 설계해야 한다
일반적인 통합 구현은 송수신 시스템과 모듈, 중계 시스템, 연계 데이터, 네트워크로 구성된다
· 로그(log)
사용자가 컴퓨터에 요청한 명령이나 컴퓨터가 데이터를 처리하는 과정 및 결과 등을 기록으로 남긴 것
· 연계 메커니즘
데이터의 생성 및 전송을 담당하는 송신 시스템과 데이터 수신 및 운영 DB반영을 담당하는 수신 시스템으로 구성된다
송수신 시스템 현황을 모니터링 할 수 있는 중계 시스템을 설치 할 수 있다
· 연계 메터니즘 과정 (모든 log 기록)
1) 송신 시스템 송신 모듈
| 연계 데이터 생성 및 추출 | 코드 매핑 및 데이터 변환 | 인터페이스 테이블 또는 파일 생성 | 연계 서버 또는 송신 어댑터 |
2) 수신 시스템 수신 모듈
| 연계 서버 또는 수신 어댑터 | 인터페이스 테이블 또는 파일 생성 | 코드 매핑 및 데이터 변환 | 운영 DB에 연계 데이터 반영 |
· 연계 메커니즘의 연계 방식
1) 직접 연계 방식
중간 매개체 없이 송수신 시스템이 직접 연계하는 방식
종류 : DB Link, API, DB Connection, JDBC 등
2) 간접 연계 방식
송수신 시스템 사이에 중간 매개체를 두어 연계하는 방식
종류 : 연계 솔루션, ESB, 소켓(Socket), 웹 서비스(Web Service)
· 연계 서버
데이터를 전송 형식에 맞게 변환하고 송수신을 수행하는 등 모든 처리를 수행
· 송신 시스템
인터페이스 테이블 또는 파일의 데이터를 전송 형식에 맞도록 변환 및 송신을 수행하는 시스템
· 수신 시스템
수신 데이터를 인터페이스 테이블이나 파일로 생성하는 시스템
· 연계 테스트
구축된 연계 시스템과 구성 요소가 정상적으로 동작하는지 확인하는 활동
연계 시스템의 주요 구성 요소 : 송수신 모듈, 연계 서버, 모니터링 현황
연계 테스트 진행 순서 : 연계테스트 케이스 작성 → 연계 테스트 환경 구축 → 연계 테스트 수행 → 연계 테스트 수행 결과 검증
· 연계 데이터 보안
송신 시스템에서 수신 시스템으로 전송되는 연계 데이터는 보안에 취약할 수 있으므로 데이터의 중요성을 고려하여 보안을 적용해야 한다
| 전송 구간 보안 | 전송되는 데이터나 패킷을 쉽게 가로챌 수 없도록 암호화 기능이 포함된 프로토콜을 사용 |
| 데이터 보안 | 송신 시스템에서 연계 데이터를 추출할 때와 수신 시스템에서 데이터를 운영 DB에 반영할 때 암호화, 복호화 하는 것 |
· XML(eXtensible Markup Language)
특수한 목적을 갖는 마크업 언어를 만드는 데 사용되는 다목적 마크업 언어
웹브라우저 간 HTML문법이 호환되지 않는 문제와 SGML의 복잡함을 해결하기 위해 개발되었다
사용자가 직접 문서의 태그를 정의할 수 있으며 다른 사용자가 정의한 태그를 사용할 수 있다
트리 구조로 구성되어 있어 상위 태그는 여러 개의 하위 태그를 가진다
· SOAP(Simple Object Access Protocol)
네트워크 상에서 HTTP/HTTPS, SMTP 등을 이용하여 XML을 교환하기 위한 통신 규약
웹 서비스에서 사용되는 메시지의 형식과 처리 방법을 지정한다
기본적으로 HTTP 기반에서 동작하기 때문에 프록시와 방화벽의 영향 없이 통신할 수 있다
SOAP대신 RESTful 프로토콜을 사용하는 추세이다
· WSDL(Web Service Description Language)
웹 서비스와 관련된 서식이나 프로토콜 등을 표준적인 방법으로 기술하고 게시하기 위한 언어
XML로 작성되며, UDDI의 기초가 된다
SOAP, XML 스키마와 결합하여 인터넷에서 웹 서비스를 제공하기 위해 사용된다
클라이언트는 WSDL 파일을 읽어 서버에서 어떠한 조작이 가능한 지를 파악할 수 있다
[정보처리기사실기 요약정리] 요구사항확인
· 소프트웨어 생명 주기(Software Life Cycle) 소프트웨어를 개발하기 위한 설계, 운용, 유지보수 등의 과정을 각 단계별로 나눈 것 소프트웨어 개발 단계와 각 단계별 주요 활동, 활동에 대한 산출물
prinha.tistory.com
그래프의 탐색 방법 출처 : https://yganalyst.github.io/concept/algo_cc_book_3/
[Algorithm] 깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS)
매일매일 알고리즘 공부하기
yganalyst.github.io
트리 구조 출처 : https://yoongrammer.tistory.com/68
[자료구조] 트리 (Tree)
목차 트리 (Tree) 트리 (Tree)란 노드들이 나무 가지처럼 연결된 비선형 계층적 자료구조입니다. 트리는 다음과 같이 나무를 거꾸로 뒤집어 놓은 모양과 유사합니다. 트리는 또한 트리 내에 다른 하
yoongrammer.tistory.com
트리의 종류와 순회 출처 : https://it-and-life.tistory.com/164
[자료구조] 트리(Tree) - 트리의 종류, 3가지 순회방법
아래의 유툽영상을 바탕으로 작성되었습니다. 좋은영상 감사합니다. Tree의 종류 : https://youtu.be/LnxEBW29DOw 0. 트리(tree)란? 즉 Array, LinkedList, Stack, Queue같이 선형구조가 아닌, 부모자식의 관계를 가지
it-and-life.tistory.com
'License' 카테고리의 다른 글
| [정보처리기사실기 요약정리] 인터페이스 구현 (0) | 2023.07.04 |
|---|---|
| [정보처리기사실기 요약정리] 서버 프로그램 구현 (0) | 2023.06.29 |
| [정보처리기사실기 요약정리] 요구사항확인 (0) | 2023.06.07 |
| [정보처리기사필기] 5과목 정보시스템 구축관리 기출문제 해설 요약정리 (0) | 2023.05.07 |
| [정보처리기사필기] 4과목 프로그래밍 언어 활용 기출문제 해설 요약정리 (0) | 2023.05.06 |



